
When working with time-series data size matters. If we can reduce the size of a database by 90% storage and transfer costs go down by 90%. What’s more, the data can be transferred or loaded 10 times faster.
Moonshadow Mobile introduced MMZIP earlier this year and we started reporting compression ratios that are much higher than those of existing technologies such as GZIP or BZIP2. Some people have asked us how this is possible. In this post we’ll share some insights on how we achieve these high compression ratios. All time-series data includes a field to store the date and time and we will use this DateTime field as an example. We will use a precision of one second in this example but the same principles work for sub-second data.
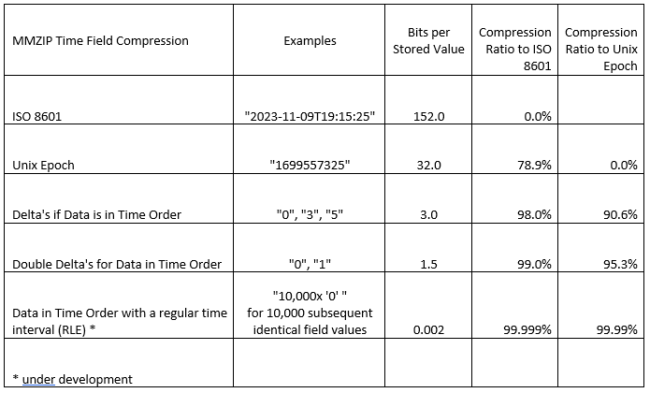
A DateTime field includes the date and the time a record was recorded. If we use the ISO 8601 standard a record has the following form: “2023-11-06T23:30:05”. If we store this data in this form it will take 152 bits. The same information can be stored as a Unix Epoch. This reduces the data to a 32-bit integer and takes the following form: “1699315405”. Storing a DateTime as a Unix Epoch instead of an ISO 8601 value results in an immediate savings of almost 80%. We are purely talking about the storage space here. It does not matter if you want to use the human readable form of ISO 8601 as an input or output. Libraries exist to convert one into the other.
Much larger savings can be achieved if we start to store the data as ‘Deltas’. When we store data as a Delta we are storing the difference between the current record and the previous record. The resulting DateTime value for a record is now calculated on the fly. A Delta is usually a small number and there are encoding schemes that result in small numbers being encoded in a smaller number of bits. Time-series data is generated as time goes by. The data generation, therefore, is in the order of time. If the data is also stored in time order then the delta’s can become very small numbers. Using Delta’s also reduces the storage size if the data is stored in time order per object – but not necessarily across all objects. If we have data on a single object then the delta is the recording interval of the IoT device (or mobile App, or Connected Vehicle). We can store these small numbers in just three bits and our savings for the DateTime field are now 98% as compared to ISO 8601 or 90% as compared to Unix Epoch.
Instead of storing the Delta we can store Double Delta’s. Whereas a Delta stores the change with the last field a Double Delta stores the change in the change. With time-series data generated by thousands of objects that is stored in time order most of the Double Delta’s will have a value of “0” with an occasional “1” when it jumps to the next second. By doing this the storage space is further reduced to around 1.5 bits per stored value. We’re now at a 99% savings compare to ISO 8601 and 95% compared to the Unix Epoch.
So how do we get to (almost) zero? For this we can use a technology called Run-Length Encoding (RLE). If we track, say, 50,000 vehicles that report their location every five seconds we will receive, on average, 10,000 timestamps every second. If the data is stored in the order of time then we will have 10,000 subsequent identical timestamps and the timestamp delta for all these records is zero (‘0’) 10,000 times. Instead of storing the actual values, delta’s or double-delta’s we can store that the zero change value repeats 10,000 times. This information takes about 20 bits to store so the space used per record for this field is 20/10,000 or 0.002 bits. We have now reduced the space taken up by the datetime field by 99.999% as compared to ISO 8601 and 99.99% as compared to the space taken up by storing the Unix Epoch timestamp. Please note that the form of the input and output values is not affected by how the data is stored. There is no loss of information and the ISO 8601 syntax or the Unix Epoch can be generated in the output stream.
The table below shows examples of the syntax for the stored values as well as the compression ratios.
MMZIP automatically determines which compression technology is best for each column. MMZIP reads in the first one million records, puts these in time order, and then determines which compression technique to use for each column. If, in a subsequent set of records, the data changes MMZIP will adjust automatically from that point forward. If there is a break in the time order, for instance, MMZIP will adjust the technique. Please note that if data is largely in order of time these compression techniques will still yield excellent results. We will occasionally have to store a new ‘beginning’ timestamp but the overhead for this is very small.
The above approach shows why MMZIP compression ratios are so much better than GZIP or BZIP2. These technologies were developed to compress text strings. GZIP and BZIP read in data as text strings and they do not recognize columns. This means they can not use the above techniques.
When you use a database technology or an off the shelf compression technology you do not usually have the ability to specify how to store the data for each field on a bit level. This means that the above technologies are not easily accessible to DBA’s or data pipeline engineers. Moonshadow has developed MMZIP specifically for engineers to take advantage of these techniques without having to develop the underlying technology themselves. Moonshadow also offers engineering services to analyze and optimize data pipelines. As the above example illustrates the savings in size, time and cost can be very significant.

{kind=link}